Metadata
Labels
Basis
...
metadata:
name: myObjectName
labels:
myLabel1: myValue1
myLabel2: myValue2
Lalbels on ReplicasSets
...
metadata:
name: myObjectName
# Labels of the ReplicaSet
labels:
myLabel1: myValue1
myLabel2: myValue2
...
spec:
replicas:3
selector
# Lables used by the ReplicasSet to discover its pods
matchLabels:
myLabel1: myValue1
template:
metadata:
# Labels of the pods
labels:
myLabel1: myValue1
myLabel2: myValue2
Annotations
Annotations are used to add information (e.g. tools name or version).
...
metadata:
name: myObjectName
annotations:
myAnnotation1: myValue1
myAnnotation2: myValue2
Node and Scheduling
Nodes
Nodes are where the Pods run. A Node can be a physical or a virtual machine.
Nodes carrying the Kubernetes API are called Control Plane Nodes. Nodes obeying the API and owning Kubelets are called Workers Nodes.
Manual Scheduling
New Pod
If the pod is not created yet, simply add the nodeName property.
spec:
nodeName: myNode
Already Created Pod - Method 1 (kubectl --force)
Add the nodeName property to the pod definition file and apply it with --force
kubectl apply --force -f myPodDefinition.yml
Already Created Pod - Method 2 (Binding Object)
Create a Binding Object and send a POST request to the pods binding api (/binding/).
apiVersion: v1
kind: Binding
metadata:
name: myPod
target:
apiVersion:v1
kind: noode
name: myNode
# Convert the binding object to JSON and use it as the data
curl http://<myHost>/api/v1/namespaces/<myNamespace>/pods/<myPod>/binding/ \
-X POST \
-H "Content-Type:application/json" \
--data {...}
Scheduler
The role of the Scheduler is to find a Node to deploy pending Pods. To do that it uses a series of plugins:
- Queue
PrioritySort: Prioritises pods scheduling based on thepriorityClassNamepod spec value (high number means higher priority).
- Filtering
NodeResourcesFit: Filters nodes that can recieve pods based on the podrequestsspec.NodeName: Filters nodes that doesn't match the value ofnodeNamepod spec.NodeUnschedulable: Filters nodes that have theUnschedalebleflag set totrue.TaintTolerationNodePortsNodeAffinity
- Scoring
NodeResourcesFit: Scores nodes that can recieve pods based on the podrequestsspec.ImageLocality: Associates higher score to nodes that alerady have the image.TaintToleration- `NodeAffinity
- Binding
DefaultBinder: Provides binding mechanism.
Custom Scheduler
Specify a custom Schduler for a pod.
spec:
schedulerName: my-scheduler
Taints and Toleration
# Pod toleration
spec:
tolerations:
- key: "spray"
operator: "Equal"
value: "mortein"
effect: "NoSchedule
Node Affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: Exists
Requests and Limits
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Basic Resources
Namespaces
Namespaces are folders used to isolate projects from one another (can be seen as "virtual clusters").
Pods
A Pod is a coherent set of one or more containers. Container in the same pods can communicate with each other directly.
Command and Args
Note: command overrides the ENTRYPOINT of a container and args overrides the CMD.
spec:
container:
-name: myContainer
image: ubuntu
command: ['sleep','5000']
args: ["--myArg"]
spec:
containers:
- name: ubuntu
image: ubuntu
command:
- "sleep"
- "1200"
args:
- "--myArg"
Environment Variable
spec:
containers:
- name: ubuntu
image: ubuntu
env:
spec:
containers:
- name: ubuntu
image: ubuntu
env:
# Classic variable
- name: myVar
value: myValue
# One value from Config Map
- name: myVar
valueFrom:
configMapKeyRef:
name: myConfigMap
key: myVar
# One value from Secret
- name: myVar
valueFrom:
secretKeyRef:
name: mySecret
key: myVar
# All values from Config Map
envFrom:
- configMapRef:
name: myConfigMap
# All values from Secret
envFrom:
- secretRef:
name: mySecret
Sidecar
Additional helper container that run in a Pod to complement functionalities of the main container.
Security Contexts
# Secruity Context for a Pod
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
supplementalGroups: [4000]
# Secruity Context for a Container
containers:
- name: sec-ctx-4
image: gcr.io/google-samples/hello-app:2.0
securityContext:
capabilities:
add: ["NET_ADMIN", "SYS_TIME"]
Jobs
A Pod to run a task. When the task is completed, the pod is destroyed. However, if the task failed, the job will try to create a new pod.
Deployments
Deployments are objects that run and scale containers. A Deployment define the number of replicas of pods desired. If a pod fail, the Deployment will recreate it.
To avoid creation failure of a pod using a Persistent Volumes Claim, configure the Strategy to type:Recreate. This will unmount the volume, destroy the pod, and then mount the volume to the new pod.
Rolling Update Strategy:
spec:
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
Recreate Strategy
spec:
strategy:
type: Recreate
Stateful Sets
Similar to Deployments with some additional the features:
- Define Volume Claim Templates that can dynamically create Persistent Volume Claims.
- Each pod will have a DNS name with this format:
statefulsetName-ordinal.serviceName.namespaceName.svc.cluster.local. There will be A record and SRV records. - By default, Stateful Set will deploy pods in sequential order. To deploy all pods simultaneously, use the spec
podManagmentPolicy: Parrallel.
Environment Variables
ConfigMap
ConfigMaps are used to store environment variables.
apiVersion: v1
kind: ConfigMap
metadata:
name: myConfigMap
data:
myVariable: "myValue"
Secret
Secrets are used to store sensitive information.
Networking
DNS
Here are some examples of working DNS names to access Pods in a Cluster:
- my-pod.my-namespace
- my-pod.my-namespace.svc
- my-pod.my-namespace.cluster.local
- my-service.my-namespace
CNI
By default, Kubernetes does not provide any networking functionality. It is required to install a CNI (Container Network Interface) plugin.
Some plugins like kindnet and flannel don't support network policies.
Others like Cilium and Calico support network policies.
Network Policies
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: internal-policy
namespace: default
spec:
podSelector:
matchLabels:
name: internal
policyTypes:
- Egress
egress:
- to:
- podSelector:
matchLabels:
name: my-webapp
ports:
- protocol: TCP
port: 8080
- to:
- podSelector:
matchLabels:
name: my-db
ports:
- protocol: TCP
port: 3306
Service
Basis
A Service is an object that manage internal access to pods in a cluster (sort of Load Balancer with Port Forwarding). Create an abstraction layer to communicate between containers inside a cluster.
Services use label selectors to pods IPs.
There are 3 types of Services: ClusterIP, NodePort and LoadBalancer.
ClusterIP
Service of type ClusterIP allows for communication between services in the same cluster only.
NodePort
Service to expose Pods outside the cluster.
All traffic send to the specified port on the Node will be sent to the pods (this requires that the client is able to directly reach nodes).
Notes
- If the request is sent to a different Node than the Pod is running on, the request will be forwarded to the right Node.
- Ports supported for this method are from
30000to32767. - A
NodePortService sends the traffic to aClusterIPwhich then sends it to the Pods.
Use case:
- When using a Load Balancer Service is too expensive or not possible (no Load Balancer Class).
- Not recommended for production
- Requires exposing nodes to clients.
- If using a DNS record, it needs to be updated frequently to match Nodes IPs.
LoadBalancer
Default method to expose a service. Depends on the Cloud Controller Manager. This type of service can be used for any kind of protocols.
AWS NLB
Creates an NLB (Layer 4 Load Balancer). This Load Balancer can be configured with specific annotations.
Configuration
# New configuration (eks >= v1.22)
kind: Service
spec:
type: LoadBalancer
loadBalancerClass: nlb
# Old configuration
kind: Service
spec:
type: LoadBalancer
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: external
Annotations
Here are some annotations that could be usefull:
metadata:
annotations:
# Use Instance mode
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: instance
# Use IP mode
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
# Configure a Load Balancer with public IP address
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
# Configure a Load Balancer with only a private IP address (accessible only in the VPC).
service.beta.kubernetes.io/aws-load-balancer-scheme: internal
AWS Classic LB (Legacy)
If the AWS Load Balancer Controller is not installed or the aws-load-balancer-type annotation is not set to nlb-ip or external, AWS will use the Legacy Load Balancer and deploy an AWS Classic Load Balancer.
Configuration
kind: Service
spec:
type: LoadBalancer
Ingress
Basis
An Ingress is an object that manage external access to services in a cluster (sort of Reverse Proxy). When using an Ingress Controller, all services will share a Load Balancer.
Ingress only allow the use of HTTP and HTTPS.
There are many types of Ingress Controllers: Nginx, Kong, Istio, ...
Nginx Ingress Controller
Nginx Ingress Controller is a pod that will act as a Reverse Proxy in the cluster. When installing Nginx controller in Cloud Managed clusters, it will create a layer 4 Load Balancer. Layer 4 Load Balancer does not understand TLS, so it will not terminate TLS.
Helm Installation Configuration
https://kubernetes.github.io/ingress-nginx/deploy/
# Values files for Helm Chart
---
controller:
ingressClassResource:
name: external-nginx
service:
annotations:
# Configuration when using with AWS Load Balancer Controller
service.beta.kubernetes.io/aws-load-balancer-type: external
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ClusterIP
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facinge
Resource Configuration
king: Ingress
spec:
ingressClassName: nginx
Architecture Example
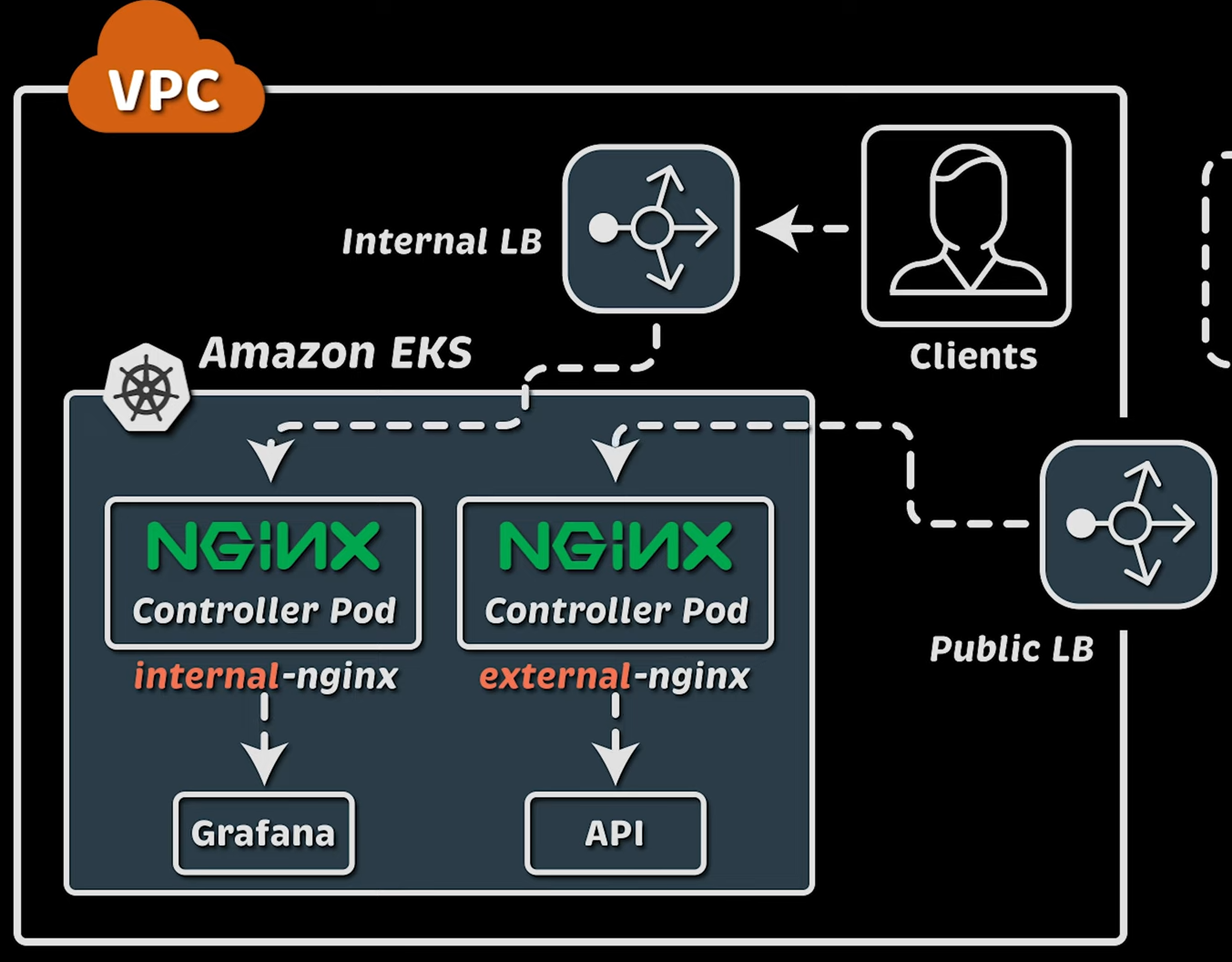 Source: Anton Putra
Source: Anton Putra
Here are some annotations that could be usefull when using an Ingress of type Nginx.
metadata:
annotations:
# Allow to do /myapp -> /
nginx.ingress.kubernetes.io/rewrite-target: /
# Redirect HTTP traffic to HTTPS
nginx.ingress.kubernetes.io/ssl-redirect: "true"
AWS ALB Ingress (AWS Load Balancer Controller)
AWS Ingress, creates an ALB (Layer 7 Load Balancer). This Load Balancer understand TLS and will terminate it when passing traffic to the cluster.
- Anton Putra - Expose Kubernetes Services Running on Amazon EKS (9 Ways)
- Anton Putra - Native EKS Ingress: AWS Load Balancer Controller
Configuration
kind: Ingress
spec:
ingressClassName: alb
Annotations
Here are some annotations that could be usefull:
metadata:
annotations:
# Listen on ports 80 and 443
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP:80}, {"HTTPS":443}]'
# Redirect HTTP traffic to HTTPS
alb.ingress.kubernetes.io/ssl-redirect: 443
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
# Set a custom healthcheck path
alb.ingress.kubernetes.io/healthcheck-path: /health
Volumes
Persistent Volume
Persistent volumes provide a file system that can be mounted to the cluster and accessible to any node.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-log
spec:
capacity:
storage: 100Mi
hostPath:
path: /pv/log
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
Reclaim Policies (persistentVolumeReclaimPolicy):
- Retain: Volume is not destroyed but is not available.
Persistent Volume Claim
Volume attached to a Pod. It's a subsection of a Persistent Volume.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim-log-1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Mi
Volume Binding Modes (VolumeBindingMode)
WaitForFirstConsumer: this will delay the binding and provisioning of aPersistentVolumeuntil a Pod using thePersistentVolumeClaimis created.
Pod Volume Mount
Inline volume declaration
spec:
containers:
volumeMounts:
- name: log-volume
mountPath: /log # Path in the container
volumes:
- name: log-volume
hostPath:
path: /var/log/webapp # Path on the host
Persitant Volume Claim
spec:
containers:
volumeMounts:
- name: log-volume
mountPath: /log # Path in the container
volumes:
- name: log-volume
persistentVolumeClaim:
claimName: claim-log-1
Autoscaling
Cluster Autoscaler
Node autoscaling.
Karpenter
Karpenter is a Cluster Autoscaler that create nodes spcificly sized for the pending pods.
Pod Autosclaer
Horizontal Pod Autoscaler
Use metrics from the Metric Server to adjust the number of replicas.
The HPA relies on the requets part of a deployment to compute the usage:
resources:
requets:
memory: 256Mi
cpu: 100m
limits:
memory: 256Mi
cpu: 100m
If the resource block on a Deployment is not defined, the HPA target will show Unkown.
Warning: Do not use replica on Deployments or Stateful Sets when using GitOps tools because they will be in concurrence to set the number of replicas. Instead, use minReplicas and maxReplicas.
Event Driven Horizontal Pod Autoscaler (Kada)
Autocaler for Event Driven platforms (Kafka, RabbitMQ, ...). It scales the app based on the number of message in a queue. Can scale down to 0 when there are no messages int the queue.
Vertical Pod Autoscaler
Autoscaler for scaling applications vertically (e.g. a standalone database). Do not use it on application that can scale horizontally. The controller for Vertical Pod Autoscaler do not come with Kubernetes by default.
There are 3 modes:
- Recreate: Recreate a new pod with updated needed resources.
- Initial: Only when deploying the application
- Off: Only provide recommendations without doing anything.
Monitoring
Metrics Server
Metrics Server get the metrics (CPU and RAM) by scrapping the Kubelet of each node.
It then serves those metrics via the Metrics API: metrics.k8s.io
Prometheus
Prometheus: service that can get advanced metrics (Latency, Traffic, Errors, Saturation, ...).
Prometheus Operator: manage lifecycle of Prometheus instances and convert Service and Pod Monitors to Prometheus configuration.
Service Monitor: Service that will scrap the app and store metrics in the Prometheus instance.
Prometheus Adapter: Convert Prometheus metrics to usable metrics for Horizontal Pod Autoscaler. It serves thoses metrics to custom.metrics.k8s.io.
Note: It is possible to replace the Metrics Server by Prometheus by adding cAdvisor and a Node Exporter on each nodes.